AI plays Zork

I was reading Hacker News the other day and saw an article of connecting Claude Code to Roller Coaster Tycoon (RCT), now having AI play games is nothing new, in fact I recall previously somebody wrote a Claude Code driven version of “Twitch Plays Pokemon” (a mechanic where viewers could comment on the twitch channel chat to control the instance of Pokemon being streamed).
As for the RCT article I find it interesting that they approached the problem by building text based tools so Claude Could communicate with the game, given the multi-modal capabilities of recent models in-game screenshots are a possibility although I would guess an expensive one.
However, why not pair text models with text games? plenty of old games are text only, there is a dozen of text adventure games available.
It occurred to me that Zork (and its ilk) are a pretty good match for this kind of experiments, I browsed around and as expected nothing is new under the sun, somebody already wrote a ChatGPT plays Zork, however, I wanted to experiment more with smaller models, I would not be surprised that frontier models are sophisticated enough to play a round of Zork, however, what is the minimum capabilities and scaffolding needed to get a reasonable playthrough?
Because this is more of a curiosity experiment I put Kiro (previously AmazonQ) to the task to write some quick scaffolding over Frotz (a Z-Machine emulator that can run Zork games with the original data files), a simple request/response class to drive the model and Kiro implemented llama.cpp, OpenRouter, Bedrock and other providers for my testing.
For my initial experimentation I choose SmolLM3, I have been experimenting with it before and found it fairly capable for its size and performant on my machine (a 24GB M4 MacBook).
I setup a simple game loop, the LLM message list is initialized with the system prompt, then the game is called to fetch the output, pass it to the LLM and then pipe the command back to the game, repeat.
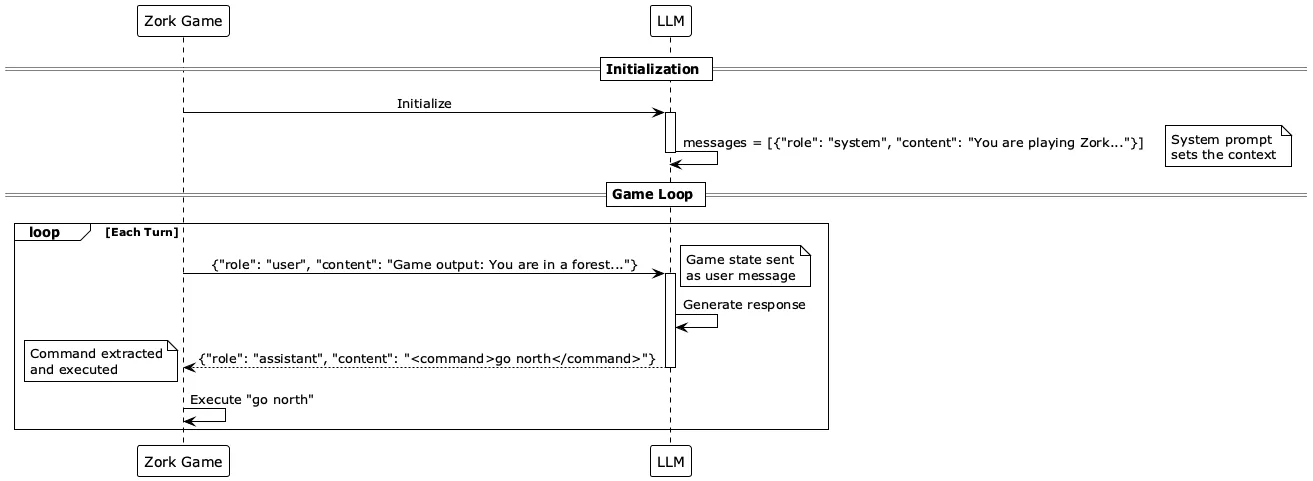
Now, getting this loop to work requires more than just simple pairing of inputs and outputs.
The system prompt is very important to steer the model into the right direction, I tried a few different things such as no prompt (whatever the default was), simple “you are a zork player”, and more elaborated setups giving detailed instructions on how to interact with the game.
The more explicit instructions worked more reliably, because the next issue is to parse the LLM output, the output can contain different things depending on the model and configuration, I first tried to get the command to execute as is, but reasoning models tended to add a “thinking” segment or go overdrive with complex command (vs a simple take, look, north, south, open).
For this use case having structured outputs works best, even just instructing the model to use tags to surround the command and thinking improves the reliability of the output and makes it simpler to parse.
So finally I had a working loop and the LLM started to actually play the game, I got some logs setup to see all the action, however, a few issues popped out.
First the LLM tried complex commands or non existing ones, improving the system prompt helped with this by being explicit about what commands are available and instructing to simplify the commands.
Once the model was working more reliably I started to see some interesting behaviors, at times the model may get stuck repeating the same command over and over (for example looking around), I added some repeated command detection to try to steer the model to use a different command.
For reasoning models sometimes the thinking tokens uses all the token budget, so I have to play around with llama.cpp settings to get a reasonable parameter, I found that 2k new token limit worked well but tended to slow down the model, 256 worked reasonably well if some harness was present to prompt the model to be more succint if it starts going over the budget and not returning any command.
Finally as I saw runs with 20+ successful turns the context length issues started to creep in so I introduced a compaction mechanic where after N turns the system will prompt the model to summarize the conversation so far.
Tuning the compaction had big impact on performance post compaction, a simple summary often led to the model going over to attempt things it tried before and did not work or just degrade (failing to successfully complete a turn and send an appropriate command).
So I came up with an “Adventurer Log” mechanic, where the model saw the system prompt and the log prompt, initially the log prompt is empty, but as compaction happens the summary is structured as a itemized list of places visited, clues and items found, as well as tips or todo items, we then wipe the message list and start back with system message, log message (with newly summary) and a game message with the current location description (look command).
This improved the ability of the model to keep 100+ turns going, I also added support for this log to be saved to file so fresh runs have a head start.
Now seeing some of the long runs shows very interesting “behaviors”, SmolLM3 tends to get stuck seemingly fixated on reviewing a leaflet found in a mailbox in the beginning of the game, several models (llama, qwen) tended to always try to open the mailbox and review the leaflet, even if I tuned the adventurer log with hints that the mailbox is not useful.
At this point I started to try different models on OpenRouter and Bedrock, Amazon Nova models tend to do a fairly good job of exploring around and are fast (Nova Micro), however, there is some funny glitches where the model keeps asking for a machete to cutdown a dense forest impeding its path. It also has a tendency of keep checking its inventory and turning the lamp item on and off inside the house once it is able to get in. The main issue with Nova models I found is that compaction log tends to lose information vs the original log input, so it does a poor job at summarizing vs other models, perhaps some prompt tuning can help.
Eventually I tried GPT OSS 120B, the model did pretty well, it is the first model to actually get into the caverns and even defeat the troll in the basement, I wonder if this model is actually trained on Zork, there is the previous ZorkGPT project which ran tons of sessions with it.
Overall I found OpenRouter useful to test different models, however, it does get glitchy at times, sometimes model response will take very long, or return empty responses, looking at the OpenRouter logs gave me a sense that different infra providers have different latency and availability which was potentially impacting my application.
Comments
Loading comments from Mastodon...